计算机网络信息中心在大数据与食源性疾病监测交叉研究中获进展
2021-07-28
计算机网络信息中心
【字体:大 中 小】

语音播报

食源性疾病是全球重要的公共卫生和食品安全问题,近年来,食源性疾病呈现出跨区域传播、变化快、难预测的特点。依托于国家重点研发计划课题“基于多源数据的食源性疾病实时预警技术体系研究”,中国科学院计算机网络信息中心大数据部将大数据和机器学习技术与食源性疾病预测的实际需求进行深度融合,在该交叉领域取得多项研究成果,相关研究成果分别发表在Food Control、Foodborne Pathogens and Disease和JMIR Medical Informatics上。
食源性疾病致菌是导致食源性疾病的主要原因,使用数据挖掘、机器学习的方法挖掘食源性疾病因素之间潜在的关联,从而对致病菌进行识别,能够对食源性疾病的诊疗起到辅助作用。课题组提出了一种利用机器学习来识别食源性疾病致病菌的方法,从空间、时间、患者信息、暴露食品等方面提取特征,使用合适的机器学习模型来对特征进行训练和学习,从而对重要的食源性疾病致病菌进行识别,以对食源性疾病的诊疗提供辅助支持。进一步,针对食源性疾病发病情况的时空预测问题,课题组提出了基于多图结构化LSTM的时空风险预测模型,该模型能够通过构造多种空间相关性并进行动态融合,利用基于Encoder-Decoder的结构化LSTM模型同时对数据的时间依赖性和空间依赖性进行建模,实现对疾病风险的多步预测。相关研究成果发表在JMIR Medical Informatics上。
食源性疾病暴发是指发生两例及以上具有共同暴露和症状相似的食源性疾病病例,目前,食源性疾病报告监测系统基于筛选规则来发现疑似食源性疾病暴发事件,但该方法普遍存在误判的现象。为了进一步提高暴发识别和预测的准确性,课题组设计出一种基于机器学习的食源性疾病暴发识别模型。在识别暴发的同时分析各类特征和致病因素对判别结果的影响,这对医学工作者具有借鉴意义。相关研究成果发表在Foodborne Pathogens and Disease上。
基于上述系列研究成果,课题组发现大数据与机器学习技术可以在病例报告、疾病诊断、暴发识别和风险预测阶段,改善现有的食源性疾病监控系统,并在此基础上总结出机器学习驱动的食源性疾病监控系统框架,以促进未来对食源性疾病监测系统做出更智能的改进。相关研究成果发表在Food Control上。
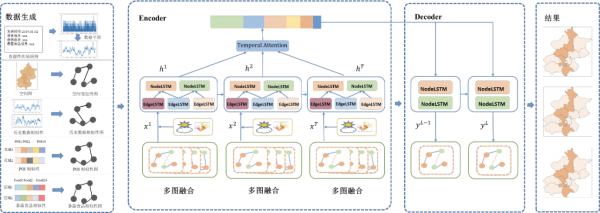
图1.食源性疾病时空风险预测模型架构
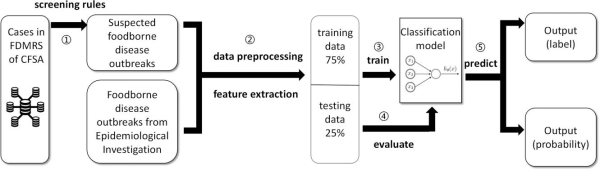
图2.基于机器学习方法的食源性疾病暴发优化
食源性疾病是全球重要的公共卫生和食品安全问题,近年来,食源性疾病呈现出跨区域传播、变化快、难预测的特点。依托于国家重点研发计划课题“基于多源数据的食源性疾病实时预警技术体系研究”,中国科学院计算机网络信息中心大数据部将大数据和机器学习技术与食源性疾病预测的实际需求进行深度融合,在该交叉领域取得多项研究成果,相关研究成果分别发表在Food Control、Foodborne Pathogens and Disease和JMIR Medical Informatics上。
食源性疾病致菌是导致食源性疾病的主要原因,使用数据挖掘、机器学习的方法挖掘食源性疾病因素之间潜在的关联,从而对致病菌进行识别,能够对食源性疾病的诊疗起到辅助作用。课题组提出了一种利用机器学习来识别食源性疾病致病菌的方法,从空间、时间、患者信息、暴露食品等方面提取特征,使用合适的机器学习模型来对特征进行训练和学习,从而对重要的食源性疾病致病菌进行识别,以对食源性疾病的诊疗提供辅助支持。进一步,针对食源性疾病发病情况的时空预测问题,课题组提出了基于多图结构化LSTM的时空风险预测模型,该模型能够通过构造多种空间相关性并进行动态融合,利用基于Encoder-Decoder的结构化LSTM模型同时对数据的时间依赖性和空间依赖性进行建模,实现对疾病风险的多步预测。相关研究成果发表在JMIR Medical Informatics上。
食源性疾病暴发是指发生两例及以上具有共同暴露和症状相似的食源性疾病病例,目前,食源性疾病报告监测系统基于筛选规则来发现疑似食源性疾病暴发事件,但该方法普遍存在误判的现象。为了进一步提高暴发识别和预测的准确性,课题组设计出一种基于机器学习的食源性疾病暴发识别模型。在识别暴发的同时分析各类特征和致病因素对判别结果的影响,这对医学工作者具有借鉴意义。相关研究成果发表在Foodborne Pathogens and Disease上。
基于上述系列研究成果,课题组发现大数据与机器学习技术可以在病例报告、疾病诊断、暴发识别和风险预测阶段,改善现有的食源性疾病监控系统,并在此基础上总结出机器学习驱动的食源性疾病监控系统框架,以促进未来对食源性疾病监测系统做出更智能的改进。相关研究成果发表在Food Control上。
论文链接:1、2、3、4
图1.食源性疾病时空风险预测模型架构
图2.基于机器学习方法的食源性疾病暴发优化
打印 责任编辑:张芳丹
责任编辑:张芳丹



















 京公网安备110402500047号 网站标识码bm48000002
京公网安备110402500047号 网站标识码bm48000002






















