郭岩,丁国栋,程学旗
(中国科学院计算技术研究所,信息智能与信息安全中心)
1 引言
2008年1月17日,中国互联网络信息中心(CNNIC)发布了《第21次中国互联网络发展状况统计报告》[1],报告显示:
(1) 截至2007年12月,网民数已增至2.1亿人。中国网民数增长迅速,比2007年6月增加4800万人,2007年一年则增加了7300万人,年增长率达到53.3%。,在过去一年中平均每天增加网民20万人。
(2) 目前中国的网民人数略低于美国的2.15亿 ,位于世界第二位。目前中国网站数量已达150万个,比去年同期增长了66万个,增长率达到78.4%。博客/个人空间等众多网络应用需求、域名数量增长的拉动及创建网站操作的简单化等因素作用在一起,共同使得网站数量猛增。
(3) 目前中国网页数为84.7亿个,年增长率达到89.4%,网上信息资源的增长速度非常迅猛。这些网页中,动静态的比例为0.92:1,动态网页的比重在逐年增高。
(4) 目前网民平均上网时长是16.2小时/周,互联网已经在网民生活中占据一定的地位。
从以上内容可见,网络作为人们获取信息的主要渠道,已成为社会生活的一部分。网络作为一种新的传媒,与报纸、无线广播和电视等传统的媒体相比,具有开放性,不确定性,交互性,超时空性以及信息量的巨大性等特点。网络不仅改变了人们的工作方式和生活方式,而且猛烈地冲击着传统的思想观念和思维方式。网络在传播现代文明的同时,也附带了各种“灰色文化”,例如色情、暴力等文化。这些不良网络文化严重污染着网络环境,尤其对生理日渐成熟、而心理并未成熟的青少年造成了极大的危害。网络的淫秽站点泛滥成灾,成为导致青少年性犯罪增加的一大诱因,也是导致暴力犯罪的一大根源。[2]在互联网的信息中,有近70%的信息有淫秽的内容。56%的人认为,通俗文化中的色情内容是导致青少年暴力的一大诱因。网络暴力文化的传播,对青少年的行为产生误导,从而导致校园暴力和有组织犯罪的增加。在互联网上,宣传暴力的文字和图片随处可见。青少年的模仿能力很强,加上暴力文化的影响,使青少年把暴力看成理所当然的事情,把犯罪看成一种游戏。
当前,不良网络文化问题已经引起了各国的重视,加强对该问题的调查和惩处是大势所趋。打击这些网络灰色文化不仅需要制定相关的法律法规,还应该利用科技工作者的聪明才智,帮助阻击或者是抑制这些灰色文化的传播泛滥。
互联网最基础的功能即提供信息。[1]目前互联网上的信息已是海量,搜索引擎则是网民在汪洋中搜寻信息的工具,是互联网上不可或缺的工具和基础应用之一。目前2.1亿网民中使用搜索引擎的比例是72.4%,即已有1.52亿人从搜索引擎获益,半年净增加3086万人。因此,为了有效的抵制网络不良文化,对于搜索引擎服务商来说,需要采取各种有效措施严格封堵过滤网络上的不良内容。
原理上,搜索引擎技术主要涉及网络搜索技术、文挡分类技术和网络信息抽取技术。其中,网络信息抽取技术是将网页中的非结构化数据或半结构化数据按照一定的需求抽取成结构化数据。网络信息抽取结果的质量将直接影响到封堵过滤网络不良内容的效率。因此,网络信息抽取技术是应对不良网络文化的关键技术之一。本文将针对网络信息抽取技术做概要性介绍。
2 网络信息抽取技术概述
2.1网络信息抽取的主要内容
网络信息抽取属于网络内容挖掘(Web content mining)研究的一部分。[3]如图1所示,主要包括结构化数据抽取(Structured Data Extraction)、信息集成(Information integreation)和观点挖掘(Opinion mining)等。
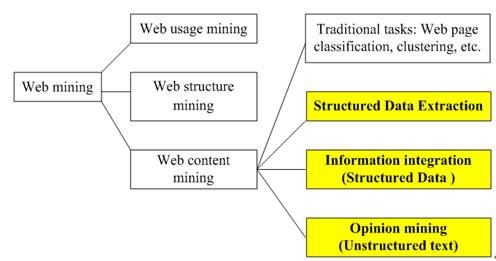
图1网络信息抽取的主要内容
结构化数据抽取(Structured Data Extraction)的目标是从Web页面中抽取结构化数据。这些结构化数据往往存储在后台数据库中,由网页按一定格式承载着展示给用户。例如论坛列表页面、Blog页面、搜索引擎结果页面等。
信息集成(Information integration)是针对结构化数据而言的。其目标是将从不同网站中抽取出的数据统一化后集成入库。其关键问题是如何从不同网站的数据表中识别出意义相同的数据并统一存储。
观点挖掘(Opinion mining)是针对网页中的纯文本而言的。其目标是从网页中抽取出带有主观倾向的信息。
大多数文献中提到的网络信息抽取往往专指结构化数据抽取。
2.2 网络数据抽取工具简介
2.2.1 工具的分类
传统的网络数据抽取是针对抽取对象手工编写一段专门的抽取程序,这个程序称为包装器(wrapper)。近年来,越来越多的网络数据抽取工具被开发出来,替代了传统的手工编写包装器的方法。目前的网络数据抽取工具可分为以下几大类(实际上,一个工具可能会归属于其中若干类)[4]:
开发包装器的专用语言(Languages for Wrapper Development):用户可用这些专用语言方便地编写包装器。例如Minerva,TSIMMIS,Web-OQL,FLORID,Jedi等。
以HTML为中间件的工具(HTML-aware Tools):这些工具在抽取时主要依赖HTML文档的内在结构特征。在抽取过程之前,这些工具先把文档转换成标签树;再根据标签树自动或半自动地抽取数据。代表工具有W4F,XWRAP,RoadRunner,MDR。
基于NLP(Natural language processing)的工具(NLP-based Tools):这些工具通常利用filtering、part-of-speech tagging、lexical semantic tagging等NLP技术建立短语和句子元素之间的关系,推导出抽取规则。这些工具比较适合于抽取那些包含符合文法的页面。代表工具有RAPIER,SRV,WHISK。
包装器的归纳工具(Wrapper Induction Tools):包装器的归纳工具从一组训练样例中归纳出基于分隔符的抽取规则。这些工具和基于NLP的工具之间最大的差别在于:这些工具不依赖于语言约束,而是依赖于数据的格式化特征。这个特点决定了这些工具比基于NLP的工具更适合于抽取HTML文档。代表工具有:WIEN,SoftMealy,STALKER。
基于模型的工具(Modeling-based Tools):这些工具让用户通过图形界面,建立文档中其感兴趣的对象的结构模型,“教”工具学会如何识别文档中的对象,从而抽取出对象。代表工具有:NoDoSE,DEByE。
基于本体的工具(Ontology-based Tools):这些工具首先需要专家参与,人工建立某领域的知识库,然后工具基于知识库去做抽取操作。如果知识库具有足够的表达能力,那么抽取操作可以做到完全自动。而且由这些工具生成的包装器具有比较好的灵活性和适应性。代表工具有:BYU,X-tract。
2.2.2 工具的定性评价
对一个抽取工具的定性评价可参考以下几个指标[4]:
自动化程度:这是个非常重要的指标。它意味着在生成包装器的同时,需要用户参与的工作量。用专用语言生成包装器的工具需要用户手工描绘要抽取的对象的边界,所以自动化程度较低。以HTML为中间件的工具往往能提供自动化程度较高的生成包装器的操作,但这种高度自动化的效果需要建立在一个假设上:被抽取页面的HTML标签具有高度的一致性。而这个假设对于现实网络中的大部分页面是不成立的。基于NLP的工具、包装器的归纳工具、基于模型的工具都可以称为半自动化工具,因为这些工具都需要用户提供样例页面,从而生成包装器。BYU这样的基于本体的工具首先需要全人工的建立知识库,但之后,只要本体有足够的表达能力,抽取操作就能够做到全自动。
是否支持复杂结构对象的处理:网页中大多数的数据呈现出复杂的结构,例如多层嵌套(multiple nesting levels)结构,如图2所示。这就需要抽取工具能够处理这些复杂的数据结构。
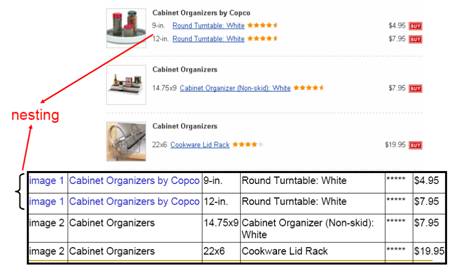
图 2 多层嵌套结构举例[3]
是否支持页面的文本分析:网页的内容,基本可分成两类:一类是半结构化数据,如图3所示;一类是半结构化文本,如图4所示。用专用语言生成包装器的工具、以HTML为中间件的工具、包装器的归纳工具、基于模型的工具往往依赖于识别出数据的边界,从而生成抽取规则,所以它们更适合处理半结构化数据。基于NLP的工具更适合处理半结构化文本。BYU这样的基于本体的工具则两者都可处理。

图 3 半结构化数据举例[4]
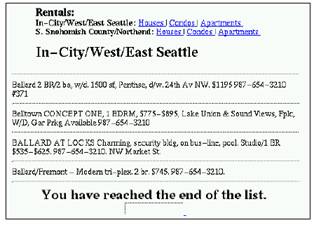
图 4 半结构化文本举例[4]
是否提供图形用户界面(GUI,Graphical User Interfaces):为了帮助用户更好地生成包装器,一些工具提供了图形用户界面。
是否支持非HTML文档:一些网页并不是用HTML写的。因为基于NLP的工具在分析时完全不依赖于HTML标签,所以非常适合处理非HTML文档。包装器的归纳工具、基于模型的工具在分析时不仅仅依赖于HTML标签,所以也可以处理一部分非HTML文档。以HTML为中间件的工具在分析时,则完全依赖HTML标签,所以不能处理非HTML文档。
灵活性(Resilience)和适应性(Adaptiveness):因为网页的结构和表达往往变化频繁,所以评价包装器的一个重要指标就是灵活性,即当网页有部分改变时,包装器是否仍然有效。另一个重要指标是适应性,即一个针对某应用领域的某种Web源的包装器是否也能对同一应用领域中的其他Web源有效。
各类抽取工具的定性评价参见图5。
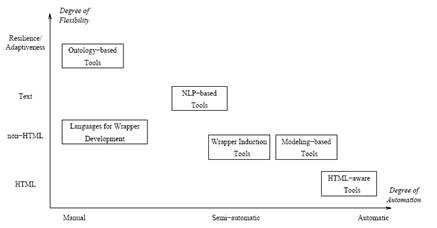
图5 各类抽取工具的评价图[4]
3 网络信息抽取的主要方法
这里重点介绍基于监督学习(supervised learning)的包装器的归纳(Wrapper induction)和基于非监督学习(unsupervised learning)的全自动抽取(Automatic extraction)。[5]
3.1 包装器的归纳
包装器的归纳是基于监督学习的方法。具体地讲,是利用机器学习生成抽取规则。主要步骤如下:
(1) 由用户在训练页面中标注要抽取的内容;
(2) 系统从训练页面中学习出抽取规则;
(3) 利用抽取规则从新页面中抽取出需要的内容。
研究人员已经研发出很多包装器归纳系统,例如WIEN[6],Softmealy[7],Stalker[8],BWI[9],WL[10]等。在这里,我们以系统Stalker作为例子介绍包装器的归纳方法。Fetch是系统Stalke的商业版本。
Stalker是一个分级包装器归纳系统。基于分级抽取的思想,它将复杂的抽取问题变成一系列简单的抽取子任务,不同级别的抽取相互独立。该系统非常适合抽取多层嵌套结构的数据记录。
Stalker在抽取过程中使用了内嵌目录树结构,即EC树(Embedded catalog tree)。EC树基于类型树(Type tree)。图6为一个网页片段,图7为图6对应的类型树,图8为图6对应的EC树。

图6 一个网页片段[5]
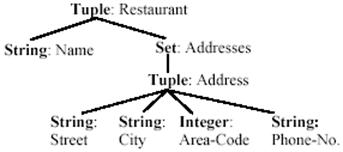
图7 图6对应的类型树[5]
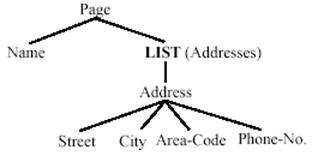
图8 图6对应的EC树[5]
如图8所示,每个抽取项对应EC树中的一个节点,包装器将使用规则从该节点的父节点中将该项内容抽取出来。对每项要抽取的内容,需要两条规则:
(1) 一条开始规则,用于检测抽取项的开始位置,即标识出抽取项对应节点的开始位置;
(2) 一条结束规则,用于检测抽取项的结束位置,即标识出抽取项对应节点的结束位置。
以上规则不仅适用于叶子节点(对应数据项),还适用于列表节点。对于列表节点,使用列表迭代规则将列表分割成一个个单独的数据记录。抽取操作之前,往往把HTML代码切分成若干个标记(token)。标记的定义一般是指标签、文本等,例如
即为一个标记。抽取过程往往以标记作为原子单位加以操作。抽取规则基于路标(landmark)的思想,每个路标是一个连续的标记序列。用路标来定位一个抽取项的开始和结束位置。下面举个例子来简要说明抽取过程。图9为图6对应的HTML代码。

图9 图6对应的HTML代码[5]
我们要抽取restaurant 的名称“Good Noodles”,可以使用以下两条规则:
R1: SkipTo() //开始规则
R2: SkipTo() //结束规则
R1告诉系统,要找到restaurant的开始路标(landmark),需要从页面对应的HTML代码的第一个标记(token)开始,跳过所有标记,直到遇到标记。在这里,标记就称为一个路标(landmark)。同样的,R2告诉系统,要找到restaurant的结束路标,需要从页面对应的HTML代码的第一个标记开始,跳过所有标记,直到遇到标记,标记也为一个路标(landmark)。
这里需要注意的是,规则可能不是唯一的。例如,下面的规则R3、R4和规则R1的效果是一样的。
R3: SkiptTo(Name _Punctuation_ _HtmlTag_)
R4: SkiptTo(Name) SkipTo()
R3表示需要跳过所有标记,直到遇到词“Name”,且该词之后紧跟着一个标点符号以及一个HTML标签(tag)。这里“Name _Punctuation_ _HtmlTag_”共同组成了一个路标。其中“_Punctuation_”和“_HtmlTag_”是通配符。
接下来我们抽取图6中的列表,其父节点对应图9中代码的第2行至第5行。为了识别整个列表,我们使用如下规则:
R5: SkipTo(
)
R6: SkipTo( )
为了将列表分割成一个个单独的数据记录,我们使用如下规则:
R7: SkipTo(
)
R8: SkipTo( )
系统在列表的父节点对应的代码中,从第一个标记开始搜索,直到遇到标记
,意味着找到了第一个数据记录的起始位置,然后接着搜索,直到再次遇到标记
,意味着找到了第二个数据记录的起始位置,…,直到代码结束。同样的,系统在列表的父节点对应的代码中,从最后一个标记开始搜索,直到遇到标记(),意味着找到了最后一个数据记录的结束位置,然后接着搜索,直到再次遇到标记(),意味着找到了倒数第二个数据记录的结束位置,…,直到代码开始。当一条数据记录的开始、结束位置被标出后,我们就能抽取其中的数据了。以上所有规则仅仅为了展示抽取过程,所以看起来比较简单。实际环境中,由于网页设计的多样性,导致规则会比较复杂。
Stalker使用连续覆盖的策略来学习抽取规则,即在训练过程中覆盖尽可能多的正例,而忽略所有反例。具体地讲,就是一旦一个正例满足了一条规则,该正例就被剔出训练集,直到所有的正例被规则覆盖。
包装器的归纳需要在学习阶段,手工标引训练例子。为了保证学习的准确性,需要大量的训练例子,因此标引工作相当费时费力。可以使用协同测试(Co-testing)等方法提高学习过程的自动化程度。
包装器的归纳还需要处理包装器的维护问题。具体地讲,就是如何解决如下难题:
(1) 包装器的检测:当一个网站发生了变化,相应的包装器能否知道这种变化?
(2) 包装器的修复:当网站的变化被正确检测到,怎样自动修复包装器?
解决以上两个问题的方法之一就是学习出要抽取内容的特征模板,用这些模板监控抽取操作,及时判断抽取结果的正确与否。一旦发现错误,当页面仅仅是格式上的较小变化时,可以用模板来定位抽取项,并重新生成包装器。解决好以上两个问题相当困难,因为往往需要上下文和语义信息来检测网站的变化,以及重新定位要抽取内容的位置。目前,包装器的维护是比较热门的研究点。
3.2 全自动抽取
基于监督学习的包装器归纳方法有以下两大不足:
(1) 手工标引的高代价,使得该方法不适合应用于大规模网站的抽取。
(2) 包装器的维护也需要付出相当大的代价。网络是个动态环境,处在不停的变化中。由于包装器归纳系统学习出的规则使用的是格式化标签,因此当一个网站改变其格式化模板时,当前的抽取规则就无效了。
针对以上不足,大家开始研究基于非监督学习的全自动抽取。实现全自动抽取是可能的,这是因为一个网站中的数据记录,往往被数量很少的固定模板所承载着,因此通过挖掘重复模式,是可以找到这些模板的。正则表达式(Regular expression)常被用来描述模板。给定一个正则表达式,可以用一个非确定有限自动机(nondeterministic finite-state automaton)在网页对应的HTML代码(可看成一个字符串序列)中作匹配,抽取出数据记录。模板也可用字符串或树模式描述。
近来比较流行的全自动抽取方法有RoadRunner[11]、MDR[12]等。方法RoadRunner将多个HTML文件作比较,找出其相似特征和不同特征,基于这些特征生成包装器。参考文献[12],我们在这里简要介绍方法MDR(Mining Data Records in Web pages)的思路。
MDR的目标是从网页中抽取结构化数据记录,例如图10所示产品列表。
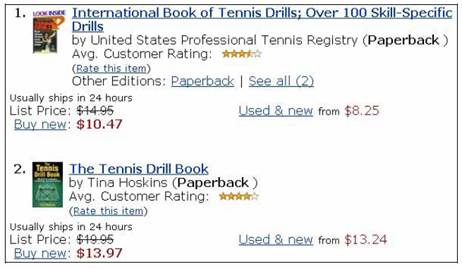
图10 结构化数据记录举例[12]
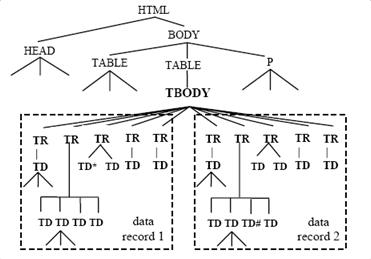
图11 图10对应的标签树[12]
方法MDR用标签树(DOM tree 或 tag tree)来描述模板。图10对应的标签树如图11所示(忽略了一些细节)。MDR的思路基于以下两个观察结果,以及串匹配算法:
(1) 一组相似的结构化数据记录可以看成一个相似对象的集合,这些对象在页面中常被放在一片邻近的区域中,该区域称为数据区域(data region),且承载每个对象的HTML标签是相似的。例如,图10中两条关于书的记录在网页中被放置在一片邻近的区域中,且每条数据记录都被相似的HTML标签序列所承载着。如果把一个页面的HTML标签看成是一个字符串,那么就能够使用字符串匹配算法来比较不同的子串,从而找出那些相似子串,这些相似子串很可能就承载了相似的对象(即数据记录)。
(2) 一个网页中的HMTL标签的内嵌结构很自然地构成一棵标签树。在一片特定区域中的一组相似的数据记录,在标签树中表现为共同拥有一个父节点。例如,图11中每个短线方框代表了一条记录。可见,每条数据记录由5个TR节点及其子树所承载,且这5个TR节点及其子树共同拥有一个父节点TBODY。也就是说,每个数据记录都被一些子树所承载着,对于一组相似的数据记录,承载它们的子树共同拥有一个父节点。
以上观察结果在实验中得到了证实。给定一个网页,MDR方法的抽取流程如下:
步骤1:为数据页面建立HTML标签树;
步骤2:基于标签树和字符串比较算法挖掘出页面中的数据区域。注意,这里并不是直接去挖掘数据记录,而是先挖掘出数据区域。例如,我们先找出图11中节点TBODY下的整个数据区域。
步骤3:从每个数据区域中识别出数据记录。例如,在图11中,这个步骤要找出TBODY下的数据区域中的数据记录1和数据记录2。
3.3 小结
基于监督学习的包装器的归纳有如下优点:
(1) 因为用户在手工标引时,明确描述了其感兴趣的抽取内容,所以抽取结果必定是用户所需要的。
(2) 因为用户在手工标引时,明确描述了从不同网站获取的数据的意义,所以抽取操作不需要考虑数据集成问题。
同时,在上节提到,包装器的归纳有以下两大不足:
(1) 手工标引代价高,使得该方法不适合大规模网站的抽取。
(2) 网站的频繁变化,使得包装器的维护需要付出相当大的代价。
基于非监督学习的自动抽取有如下优点:
(1) 由于抽取过程是完全自动的,所以非常适用于大规模网站的抽取需求。
(2) 由于抽取过程是完全自动的,所以维护代价非常小。
同时,自动抽取有如下不足:
(1) 由于没有用户参与,所以系统并不知道用户真正感兴趣的是什么内容,导致抽取结果中可能会包含很多用户不需要的数据。对这点不足,可以用领域启发式信息或手工过滤的方法从抽取结果中剔除无关数据。
(2) 从多个网站中抽取出的数据结果需要通过集成操作,才能真正入库。
在抽取精度方面,通常认为包装器的归纳比自动抽取精确,但至今并没有文献给出具体比较结果。在应用方面,包装器的归纳往往适合于要抽取的网站数量较少,且这些网站的模板数量较少的任务;自动抽取往往适合大规模的抽取任务,且这些任务不需要精确标引和数据集成。
4 结论
当前,不良网络文化问题已经引起了高度重视。为了打击网络灰色文化,不仅需要制定相关的法律法规,还应该充分利用高科技手段。搜索引擎是互联网上不可或缺的工具和基础应用之一。对于搜索引擎服务商来说,需要采取各种有效措施严格封堵过滤网络上的不良内容,从而有效的抵制网络不良文化。本文针对搜索引擎技术中的网络信息抽取技术做了概要性介绍。因为网络信息抽取结果的质量,会直接影响到搜索引擎封堵过滤网络不良内容的效率,因此,研究网络信息抽取技术对于解决不良网络文化问题是非常关键的。
参考文献
[1] 中国互联网络信息中心 (CNNIC).中国互联网络发展状况统计报告.2008.1.17.
[2] 郭新建.警惕不良文化.郑州日报,2007.7.15.
[3] B.Liu. ACM SIGKDD Inaugural Webcast: Web Content Mining, Nov 29, 2006.
[4] A. Laender, B. Ribeiro-Neto, A. Silva, and J. Teixeira. A brief survey of web data extraction tools. ACM SIGMOD Record, 31(2):84–93, 2002.
[5] B. Liu. Web Data Mining - Exploring Hyperlinks, Contents, and Usage Data. Springer, December, 2006.
[6] N. Kushmerick, D. S. Weld, and R. B. Doorenbos. Wrapper induction for information extraction. In Proc. of the Int. Joint Conf. on Artificial Intelligence, 1997.
[7] C. Hsu and M. Dung. Generating finite-state transducers for semi-structured data extraction from the web. Information Systems, 23(8):521–538, 1998.
[8] I. Muslea, S. Minton, and C. Knoblock. A hierarchical approach to wrapper induction. In Proc. of the Third Int. Conf. on Autonomous Agents, 1999.
[9] D., Freitag and N., Kushmerick. Boosted wrapper induction. In Proc. of the Conf. on Artificial Intelligence, 2000.
[10] W. Cohen, M. Hurst, and L. Jensen. A flexible learning system for wrapping tables and lists in html documents. In Proc. of the 11th Int. World Wide Web Conf., 2002.
[11] V. Crescenzi, G. Mecca, and P. Merialdo. Roadrunner: Towards automatic data extraction from large web sites. In Proc. of 27th Int. Conf. on Very Large Data Bases, 2001.
[12] B. Liu, R. Grossman, and Y. Zhai. Mining data records from web pages. In Proc. of 14th ACM SIGKDD Int. Conf. on Knowledge Discovery in Databases and Data Mining, 2003.
[13] Y. Zhai and B. Liu. Web data extraction based on partial tree alignment. In Proc. of the 14th Int. World Wide Web Conf., 2005.
[14] B. Liu and Y. Zhai. Net - a system for extracting web data from flat and nested data records. In Proc. of the 6th Int. Conf. on Web Information Systems Engineering, 2005. |

 联系我们
联系我们