






主要职责
中国科学院贯彻落实党中央关于科技创新的方针政策和决策部署,在履行职责过程中坚持党中央对科技工作的集中统一领导。主要职责是:
一、开展使命导向的自然科学领域基础研究,承担国家重大基础研究、应用基础研究、前沿交叉共性技术研究和引领性颠覆性技术研究任务,打造原始创新策源地。 更多+
院况简介
中国科学院是国家科学技术界最高学术机构、国家科学技术思想库,自然科学基础研究与高技术综合研究的国家战略科技力量。
1949年,伴随着新中国的诞生,中国科学院成立。建院70余年来,中国科学院时刻牢记使命,与科学共进,与祖国同行,以国家富强、人民幸福为己任,人才辈出,硕果累累,为我国科技进步、经济社会发展和国家安全作出了不可替代的重要贡献。 更多+
院领导集体


科技奖励
科技期刊

工作动态/ 更多



中国科学院学部
中国科学院院部

语音播报

端对端语音识别是一种利用深度学习模型将语音信号直接转变为文字的技术,其中,基于注意力机制的模型可以达到较高的识别准确率。但大多数注意力机制模型需要完整的语音信号,不适用于在线处理语音流。
针对在线语音识别的应用场景,中国科学院声学研究所语言声学与内容理解重点实验室博士生缪浩然与其导师、研究员张鹏远,助理研究员程高峰等对主流注意力机制处理语音流的性能开展研究,提出一种单调截断语音流的在线注意力机制和一套高效实时的解码算法。近日,相关研究成果在线发表在IEEE/ACM Transactions on Audio, Speech, and Language Processing上。
研究发现,语音识别系统对各时刻语音信号注意力的权重分布呈指数衰减态势,这不利于处理长时语音流;在线注意力模型训练和推理之间存在差异,导致模型性能下降。基于上述问题,研究人员在设计单调截断语音流的在线注意力模型时,优化注意力权重指数衰减特性、通过离散化注意力权重缩小训练和推理之间的差异。
基于公开的中英文语音识别数据集的实验表明,单调截断语音流的在线注意力模型在处理长时语音流时性能更稳定;基于注意力机制和联结主义时序分类准则的联合在线解码算法,在线语音识别系统的字错误率略高于离线系统,其解码速度可以达到离线系统的1.5倍。这种单调截断语音流的在线注意力机制和相关解码算法为端对端语音识别技术在大规模工业在线产品中的应用提供可行方案。
该研究得到国家自然科学基金的资助。
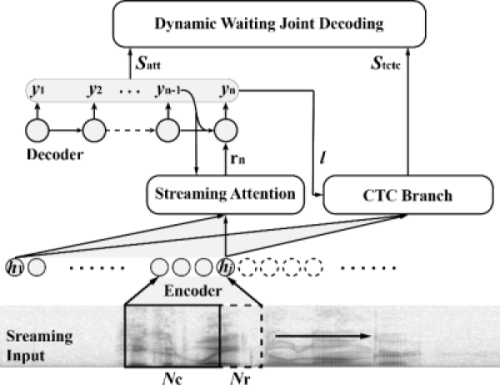
在线端对端语音识别框架





© 1996 - 中国科学院 版权所有 京ICP备05002857号-1  京公网安备110402500047号 网站标识码bm48000002
京公网安备110402500047号 网站标识码bm48000002
地址:北京市西城区三里河路52号 邮编:100864
电话: 86 10 68597114(总机) 86 10 68597289(总值班室)























